Pourquoi plus de données ne signifie pas de meilleures décisions
Écrit par
Maya Global

Article publié à l'origine en anglais.
L'usine qui est restée lente
Les moteurs électriques sont arrivés dans les usines dans les années 1880. Ils étaient clairement supérieurs aux machines à vapeur. Les propriétaires d'usines les ont achetés immédiatement.
Et puis rien ne s'est passé. La productivité n'a pratiquement pas bougé pendant 40 ans.
L'historien de l'économie Paul David a documenté ce phénomène dans un article désormais célèbre paru dans l'American Economic Review. Le schéma qu'il a identifié était frappant : les propriétaires d'usines ont pris le moteur électrique et l'ont boulonné au même endroit où se trouvait la machine à vapeur — une seule grande source d'énergie entraînant un arbre central, des courroies et des poulies distribuant l'énergie dans tout le bâtiment. L'agencement, l'organisation du travail, le flux des matériaux — rien n'a changé. Ils ont remplacé la source d'énergie mais conservé l'architecture.

Les vrais gains sont arrivés dans les années 1920, lorsque les ingénieurs ont compris que les moteurs électriques pouvaient être petits. On pouvait en placer un sur chaque machine. On pouvait réorganiser l'atelier autour du flux de travail plutôt qu'autour de la proximité d'un arbre central. La croissance de la productivité manufacturière aux États-Unis est passée d'environ 1,5 % par an à plus de 5 % — une accélération de 3,4x. Non pas parce que les moteurs étaient meilleurs, mais parce que l'architecture du travail avait changé pour correspondre à ce que la technologie permettait.
Le propos de David n'était pas vraiment à propos des moteurs. Il portait sur un schéma : lorsqu'une technologie nouvelle et puissante est insérée dans un flux de travail inchangé, les gains sont négligeables. Les gains arrivent lorsque l'on repense le flux de travail autour de ce que la technologie rend possible.
Je pense à ce schéma en permanence. Parce que notre industrie le vit en ce moment.
(Paul David, « The Dynamo and the Computer: An Historical Perspective on the Modern Productivity Paradox », American Economic Review, 1990. Pour un récit complet, Electrifying America de David Nye (MIT Press, 1990) couvre en détail la transition des usines.)
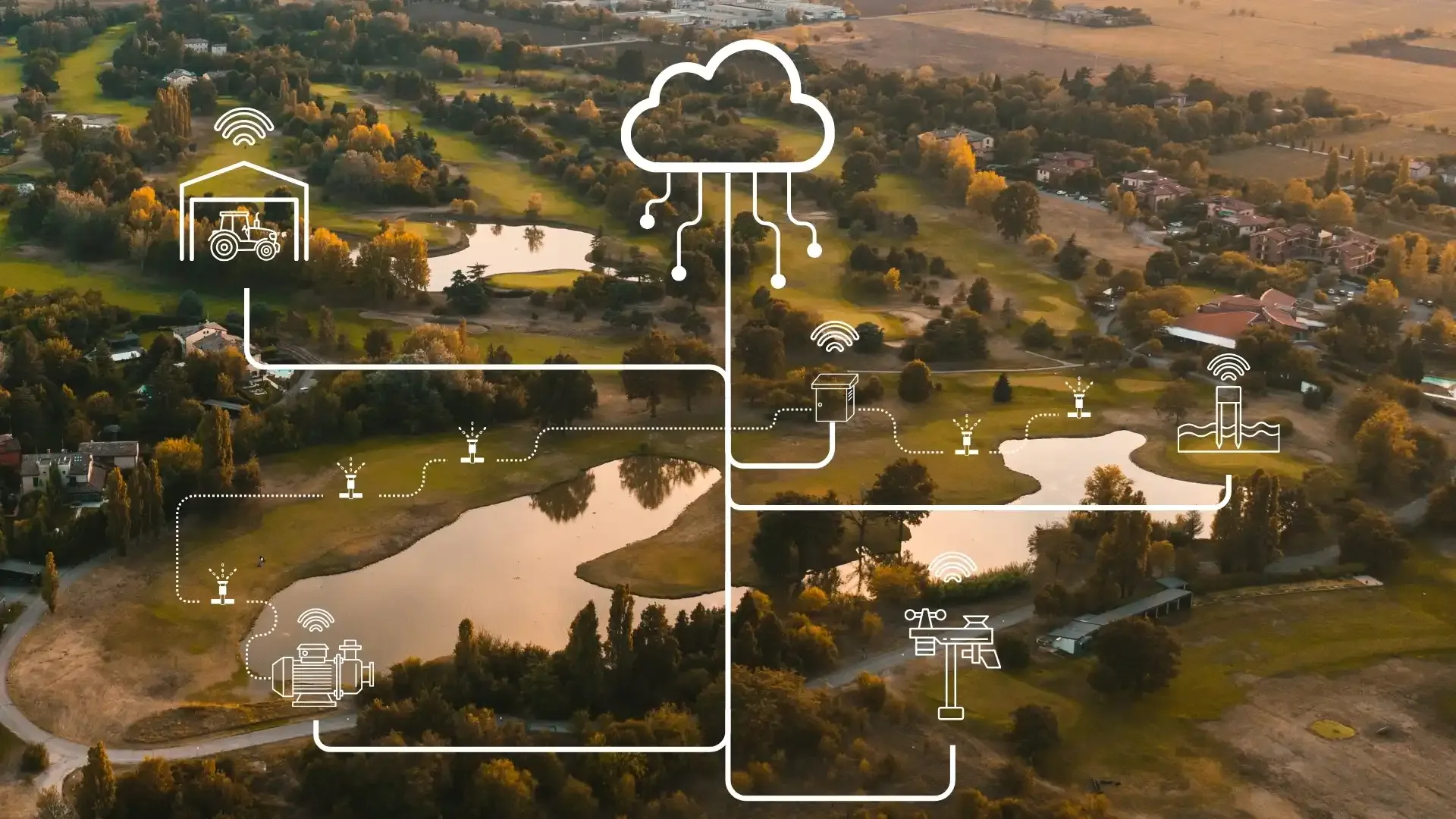
Cinq tableaux de bord et un groupe WhatsApp

Ces dix dernières années, la gestion du gazon a acquis une quantité extraordinaire de technologie. Stations météo. Capteurs d'humidité du sol. Suivi GPS des flottes. Outils de planification de la nutrition. Modèles de risque de maladie. Contrôleurs d'irrigation. Suivi de la croissance via les rendements de tonte ou les modèles GDD.
Chacun est arrivé avec son propre tableau de bord, son propre identifiant, son propre format de données. Chacun a été boulonné sur la façon de travailler existante. La routine quotidienne est restée la même — parcourir le terrain, vérifier la météo, décider quoi faire selon l'expérience — mais il y a désormais plus d'écrans à consulter d'abord.
C'est le moteur électrique boulonné dans l'usine à vapeur. La source d'énergie a changé mais l'architecture de la prise de décision, non. L'information passe toujours par la tête d'une seule personne. Le recoupement se fait toujours manuellement, s'il a lieu.
Ajouter un autre capteur, une autre application, un autre tableau de bord à cette organisation ne rend pas les décisions meilleures. Cela rallonge la matinée.
Boulonner une nouvelle capacité sur des flux de travail inchangés produit des accélérations mineures — des versions légèrement mieux informées des mêmes décisions prises de la même manière. Repenser le flux de travail lui-même — construire une architecture différente — produit des capacités fondamentalement différentes. Pas le même travail fait plus vite. Un travail différent rendu possible.
Ce que signifie vraiment l'architecture
Architecture est un mot intimidant. Il n'a pas besoin de l'être.
Voyez-le comme ceci. Vous avez cinq classeurs dans cinq pièces différentes — météo, sol, registres de pulvérisation, nutrition, matériel. Chacun est bien organisé. Mais si vous voulez répondre à « l'application d'engrais de la semaine dernière, combinée à la période chaude et aux niveaux d'humidité, a-t-elle augmenté le risque de maladie sur les greens ? » — vous devez marcher jusqu'à quatre pièces, sortir quatre jeux de dossiers et élaborer la réponse vous-même.
L'architecture, c'est mettre les cinq classeurs dans une seule pièce avec un bibliothécaire qui comprend comment ils sont reliés. Les données ne changent pas. Mais la capacité à recouper, à repérer des schémas, à répondre à des questions composées — cela change fondamentalement.
Concrètement, l'architecture des données pour une exploitation de gazon signifie trois choses :
- Toutes les données opérationnelles affluent dans une structure commune, quelle que soit leur origine
- Les relations entre types de données sont définies (l'humidité du sol est liée à la programmation de l'irrigation, le GDD est lié au moment de la nutrition, les conditions météo sont liées au risque de maladie)
- Le système peut raisonner à travers ces relations, pas seulement les stocker côte à côte
C'est la différence entre avoir des données et avoir de l'intelligence. Et cela correspond à trois stades qui décrivent où se trouvent la plupart des exploitations aujourd'hui et où elles se dirigent.
Stade 1 : Déconnecté
C'est là où se trouve la grande majorité des exploitations de gazon en 2026, et il n'y a pas de honte à cela. Les outils n'ont pas été conçus pour se parler entre eux. Personne ne s'est vu proposer d'alternative connectée.
À quoi cela ressemble à 6h du matin : vous consultez l'application météo. Vous consultez l'application de la sonde de sol. Vous ouvrez le tableur sur votre téléphone (ou non, parce qu'il n'est pas formaté pour mobile). Vous vous souvenez de ce que vous avez pulvérisé la semaine dernière. Vous estimez l'accumulation de GDD selon votre expérience. Vous prenez une décision.
La décision est souvent bonne. Les opérateurs expérimentés prennent d'excellentes décisions dans des environnements déconnectés — ils ont bâti des modèles internes au fil d'années d'observation. Le problème n'est pas la qualité de la décision. C'est le coût de sa production. Le temps passé à recouper. La charge mentale de garder six sources de données en tête avant l'arrivée de l'équipe. Les signaux que vous manquez non par manque de connaissances, mais parce que vous étiez occupé.
La limite critique au Stade 1 n'est pas la qualité des données. C'est que l'opérateur fait le travail d'intégration que le système devrait faire — et ce travail consomme le temps et l'espace mental qui devraient aller vers les décisions que lui seul peut prendre. Vous savez que le risque de fusariose augmente parce que vous avez consulté les prévisions, que vous vous êtes souvenu du moment de l'épidémie de l'année dernière et que vous avez jeté un œil à la sonde de sol. Mais vous avez fait ce travail de tête, entre le parking et l'atelier de maintenance, tout en pensant aussi à la rotation de tonte et au tournoi de samedi.
Stade 2 : Connecté
Au Stade 2, les données circulent entre les systèmes. Les données météo, les données de sol, les registres de pulvérisation, les intrants nutritionnels et le suivi de la croissance alimentent un environnement commun où ils peuvent être visualisés ensemble et recoupés.
Cela paraît simple. C'est structurellement significatif.
Lorsque l'accumulation de GDD est suivie aux côtés du programme de nutrition, vous pouvez voir si l'application d'engrais a coïncidé avec la fenêtre de croissance ou l'a manquée. Lorsque les modèles de risque de maladie tirent des données météo réelles du site plutôt que d'une prévision régionale, l'évaluation du risque reflète votre microclimat, pas une moyenne sur 30 km. Lorsque les registres de pulvérisation sont horodatés par rapport aux conditions météo, vous pouvez auditer si les applications ont eu lieu dans la bonne fenêtre — et si elles ont fonctionné.
À quoi cela ressemble à 6h du matin : vous ouvrez un seul système. Vous voyez que les températures nocturnes sont descendues à 3°C, que l'humidité du sol sur les greens est à 28 %, que l'accumulation de GDD a franchi le seuil que vous avez fixé pour votre prochaine application d'engrais, et que le modèle de risque de maladie à 10 jours montre une pression de fusariose élevée à partir de jeudi. Le registre de pulvérisation montre que votre dernière application préventive remonte à 12 jours.
Vous prenez les mêmes décisions. Mais la préparation qui prenait 20 minutes de recoupements entre cinq systèmes ne prend plus que 90 secondes de lecture. Plus important encore, les recoupements que vous auriez pu manquer — parce que vous étiez occupé, parce que vous avez oublié de vérifier la sonde de sol, parce que le tableur était sur l'ordinateur du bureau — sont désormais visibles par défaut.
Le passage du Stade 1 au Stade 2 n'a pas à voir avec de meilleures données. Il a à voir avec le fait de libérer l'opérateur du travail manuel d'intégration afin qu'il puisse se concentrer sur ce dans quoi il excelle vraiment.
Stade 3 : Intelligent
Le Stade 3 est le moment où le système cesse d'être un classeur — même bien organisé — et commence à raisonner.
Au Stade 2, le système vous montre que le GDD a franchi votre seuil de nutrition. Au Stade 3, il vous dit : « Le GDD a franchi le seuil ce matin, mais l'humidité du sol est basse et aucune pluie n'est prévue pendant cinq jours. Appliquer un engrais granulaire maintenant risque de brûler. Envisagez de retarder de 48 heures ou de passer à une application foliaire. »
Au Stade 2, vous voyez que la pression des maladies augmente. Au Stade 3, le système a déjà consulté votre registre de pulvérisation, comparé les conditions aux schémas historiques de votre site, et vous a dit : « Les conditions évoluent de façon similaire à la troisième semaine d'octobre 2025, lorsque la fusariose est apparue sur les greens 6, 11 et 14. Votre dernière application date de 12 jours. Vous approchez de la fin de la fenêtre de protection. »
Ce n'est pas de l'automatisation. L'opérateur décide toujours. Mais le système a fait le travail de préparation qui dépendait entièrement de la mémoire et de l'expérience — à travers chaque donnée, chaque enregistrement historique, chaque modèle météo, simultanément.
À quoi cela ressemble à 6h du matin : vous arrivez et le système a déjà préparé un briefing basé sur les seuils que vous avez fixés, les priorités que vous avez définies et le plan de gestion que vous avez bâti pour la saison. Voici ce qui a changé pendant la nuit. Voici ce que cela signifie par rapport à votre plan. Voici les trois choses qui nécessitent votre attention selon vos propres critères. Le reste est en bonne voie.
Le greenkeeper expérimenté en sait toujours plus que le système sur les subtilités de son site — le green qui draine toujours lentement, le microclimat derrière le clubhouse. Mais il ne dépense plus cette expertise dans le travail manuel d'intégration des données. Sa connaissance va là où elle est vraiment irremplaçable : le jugement, les priorités, et les mille petites décisions qui font un grand parcours.
Le cockpit, pas le pilote
La Formule 1 a vécu exactement cette transition. Dans les années 1980, un stratège de course prenait les décisions d'arrêt au stand avec un chronomètre, un panneau de stand et la voix du pilote à la radio. Les données existaient par fragments — le pilote sentait les pneus, le mécanicien entendait le moteur, le stratège regardait l'écart. Personne n'avait de vue connectée.

Aujourd'hui, 300 capteurs sur chaque voiture génèrent plus d'un million de points de données par seconde. Les équipes font tourner plus de mille simulations de course par week-end. La différence n'est pas qu'elles ont ajouté des capteurs. C'est qu'elles ont repensé l'architecture de décision autour de données intégrées et en temps réel.
Mais le pilote pilote toujours. La voiture doit toujours être ressentie. L'instinct qui sépare un bon tour d'un tour formidable n'a pas été remplacé — il a été amplifié. Le pilote ne se mesure pas à la télémétrie. La télémétrie donne au pilote davantage d'éléments de la situation, plus vite, pour que les décisions que seul un humain peut prendre se fassent dans un meilleur contexte.
Voilà le changement. Pas remplacer l'expertise. L'amplifier en supprimant le travail sur les données qui se place entre ce que vous savez et ce que vous faites.
Vers où cela se dirige
La destination n'est pas un système qui remplace l'opérateur. C'est un système qui l'accompagne — un copilote présent tout au long de la saison, qui construit un contexte dans la durée, qui comprend la différence entre mars sur votre site et mars sur un site à 200 kilomètres de là.
Lorsque les décisions sont prises à l'intérieur d'un système connecté, elles laissent une trace. L'application d'engrais qui a été retardée parce que l'humidité du sol était basse — cette décision est enregistrée, avec les conditions qui l'ont motivée et le résultat qui a suivi. Avec le temps, le système apprend. Pas à partir d'un manuel — à partir de votre gazon, de votre climat, de vos décisions de gestion. Chaque saison rend la suivante plus affûtée.
Les usines qui ont fini par prospérer n'étaient pas celles qui avaient acheté les meilleurs moteurs. C'étaient celles qui avaient repensé l'organisation du travail. La technologie comptait — mais l'architecture comptait davantage.
Pour la gestion du gazon, la question équivalente n'est pas « quel capteur dois-je acheter ensuite ? ». C'est : « lorsque l'information arrive sur mon site — d'une station météo, d'une sonde de sol, d'un registre de pulvérisation, d'une mesure de croissance — où va-t-elle et que se passe-t-il ensuite ? ».
La technologie pour bien répondre à cette question existe aujourd'hui. La question, comme avec le moteur électrique, est de savoir si nous sommes prêts à repenser l'architecture autour d'elle.