Por qué más datos no significa mejores decisiones
Escrito por
Maya Global

Artículo publicado originalmente en inglés.
La fábrica que siguió siendo lenta
Los motores eléctricos llegaron a las fábricas en la década de 1880. Eran claramente superiores a las máquinas de vapor. Los dueños de las fábricas los compraron de inmediato.
Y entonces no pasó nada. La productividad apenas cambió durante 40 años.
El historiador económico Paul David documentó esto en un artículo hoy famoso para la American Economic Review. El patrón que encontró era llamativo: los dueños de las fábricas tomaron el motor eléctrico y lo atornillaron en el mismo lugar donde había estado la máquina de vapor — una gran fuente de energía que hacía girar un eje central, con correas y poleas distribuyendo la energía por todo el edificio. La distribución, la organización del trabajo, el flujo de materiales — nada de eso cambió. Sustituyeron la fuente de energía pero conservaron la arquitectura.

Las ganancias reales llegaron en la década de 1920, cuando los ingenieros se dieron cuenta de que los motores eléctricos podían ser pequeños. Se podía poner uno en cada máquina. Se podía reorganizar la planta en torno al flujo de trabajo y no en torno a la cercanía a un eje central. El crecimiento de la productividad manufacturera en EE. UU. se disparó de aproximadamente un 1,5 % anual a más del 5 % — una aceleración de 3,4x. No porque los motores fueran mejores, sino porque la arquitectura del trabajo cambió para adaptarse a lo que la tecnología permitía.
La tesis de David no iba en realidad sobre los motores. Iba sobre un patrón: cuando una tecnología nueva y potente se inserta en un flujo de trabajo inalterado, las ganancias son insignificantes. Las ganancias llegan cuando se rediseña el flujo de trabajo en torno a lo que la tecnología hace posible.
Pienso en este patrón constantemente. Porque nuestro sector lo está viviendo ahora mismo.
(Paul David, "The Dynamo and the Computer: An Historical Perspective on the Modern Productivity Paradox", American Economic Review, 1990. Para el arco completo, Electrifying America de David Nye (MIT Press, 1990) cubre la transición fabril en detalle.)
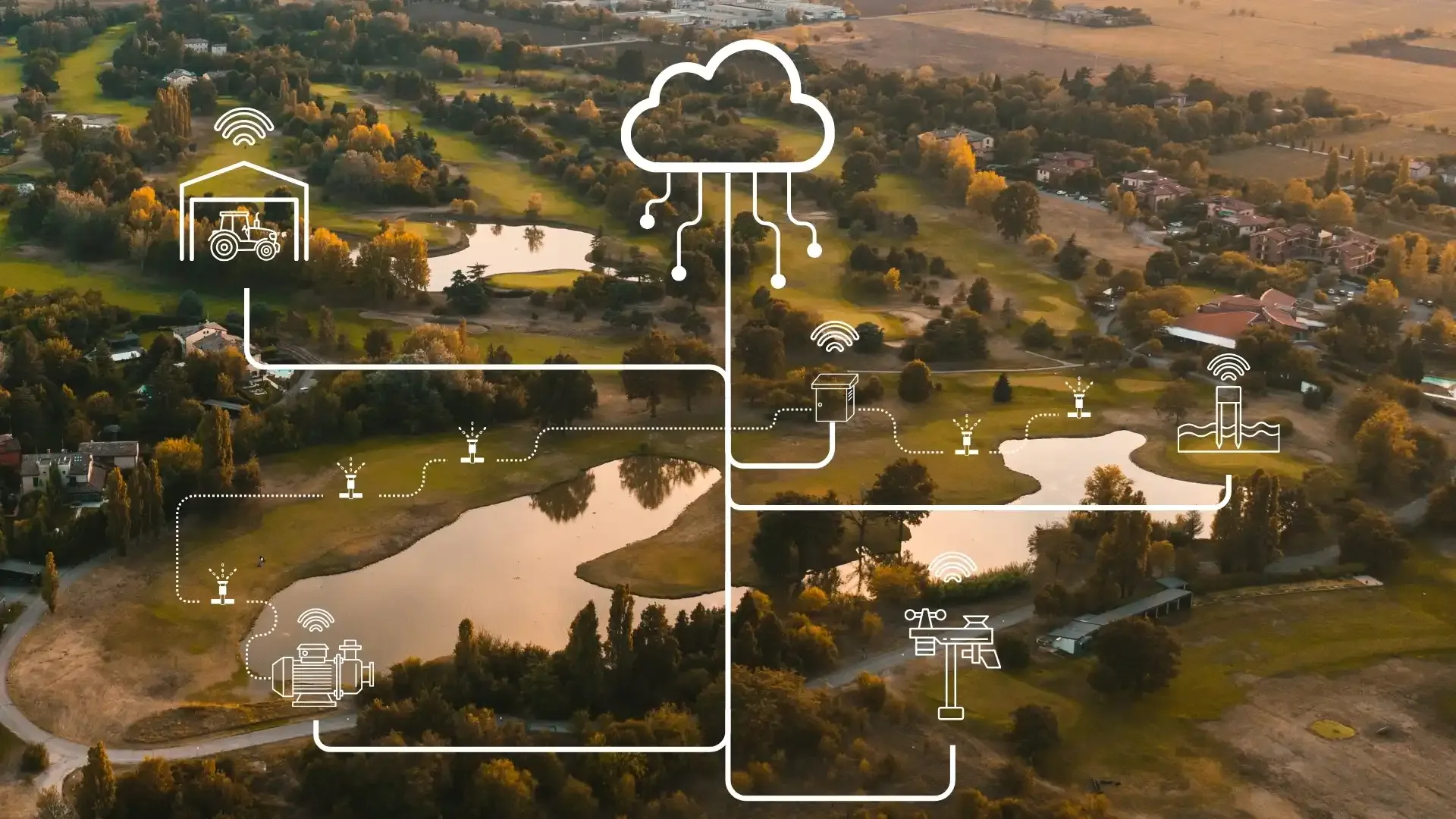
Cinco cuadros de mando y un grupo de WhatsApp

En la última década, la gestión del césped ha adquirido una cantidad extraordinaria de tecnología. Estaciones meteorológicas. Sensores de humedad del suelo. Seguimiento GPS de flotas. Herramientas de planificación nutricional. Modelos de riesgo de enfermedades. Controladores de riego. Seguimiento del crecimiento mediante rendimientos de corte o modelos GDD.
Cada uno llegó con su propio cuadro de mando, su propio inicio de sesión, su propio formato de datos. Cada uno se atornilló sobre la manera de trabajar existente. La rutina diaria siguió siendo la misma — recorrer el campo, comprobar el tiempo, decidir qué hacer según la experiencia — pero ahora hay más pantallas que mirar primero.
Este es el motor eléctrico atornillado a la fábrica de la era del vapor. La fuente de energía ha cambiado, pero la arquitectura de la toma de decisiones no. La información sigue pasando por la cabeza de una sola persona. El cruce de datos sigue haciéndose a mano, si es que se hace.
Añadir otro sensor, otra aplicación, otro cuadro de mando a esta organización no mejora las decisiones. Alarga la mañana.
Atornillar nuevas capacidades sobre flujos de trabajo inalterados produce aceleraciones menores — versiones ligeramente mejor informadas de las mismas decisiones tomadas de la misma manera. Rediseñar el flujo de trabajo en sí — construir una arquitectura distinta — produce capacidades fundamentalmente distintas. No el mismo trabajo hecho más rápido. Un trabajo distinto hecho posible.
Lo que significa realmente la arquitectura
Arquitectura es una palabra intimidante. No tiene por qué serlo.
Piénsalo así. Tienes cinco archivadores en cinco habitaciones distintas — tiempo, suelo, registros de pulverización, nutrición, maquinaria. Cada uno está bien organizado. Pero si quieres responder a "¿la aplicación de fertilizante de la semana pasada, combinada con la ola de calor y los niveles de humedad, aumentó el riesgo de enfermedad en los greenes?" — tienes que ir a cuatro habitaciones, sacar cuatro conjuntos de archivos y elaborar tú mismo la respuesta.
Arquitectura significa poner los cinco archivadores en una sola habitación con un bibliotecario que entiende cómo se relacionan entre sí. Los datos no cambian. Pero la capacidad de cruzarlos, de detectar patrones, de responder preguntas compuestas — eso cambia fundamentalmente.
En términos prácticos, la arquitectura de datos para una operación de césped significa tres cosas:
- Todos los datos operativos fluyen a una estructura común, independientemente de dónde se generaron
- Las relaciones entre tipos de datos están definidas (la humedad del suelo se relaciona con la programación del riego, el GDD se relaciona con el momento de la nutrición, las condiciones meteorológicas se relacionan con el riesgo de enfermedad)
- El sistema puede razonar a través de esas relaciones, no solo almacenarlas lado a lado
Esta es la diferencia entre tener datos y tener inteligencia. Y se corresponde con tres etapas que describen dónde están hoy la mayoría de las operaciones y hacia dónde se dirigen.
Etapa 1: Desconectado
Aquí es donde está la gran mayoría de las operaciones de césped en 2026, y no hay nada de qué avergonzarse. Las herramientas no se diseñaron para hablar entre sí. A nadie le ofrecieron una alternativa conectada.
Cómo se ve esto a las 6 de la mañana: miras la aplicación del tiempo. Miras la aplicación de la sonda de suelo. Abres la hoja de cálculo en el teléfono (o no, porque no está formateada para móvil). Recuerdas lo que pulverizaste la semana pasada. Estimas la acumulación de GDD según tu experiencia. Tomas una decisión.
A menudo la decisión es buena. Los operadores con experiencia toman excelentes decisiones en entornos desconectados — han construido modelos internos a lo largo de años de observación. El problema no es la calidad de la decisión. Es el coste de producirla. El tiempo que se pierde cruzando datos. La carga mental de sostener seis fuentes de información en la cabeza antes de que llegue el equipo. Las señales que se te escapan no porque te falte conocimiento, sino porque estabas ocupado.
La limitación crítica en la Etapa 1 no es la calidad de los datos. Es que el operador está haciendo el trabajo de integración que debería hacer el sistema — y ese trabajo consume el tiempo y el espacio mental que deberían dedicarse a las decisiones que solo él puede tomar. Sabes que el riesgo de fusarium está subiendo porque has mirado el pronóstico, has recordado cuándo fue el brote del año pasado y has echado un vistazo a la sonda de suelo. Pero ese trabajo lo has hecho mentalmente, entre el aparcamiento y el taller de mantenimiento, a la vez que pensabas en la rotación de siega y en el torneo del sábado.
Etapa 2: Conectado
En la Etapa 2, los datos fluyen entre sistemas. Los datos meteorológicos, los datos del suelo, los registros de pulverización, las entradas de nutrición y el seguimiento del crecimiento alimentan un entorno común donde pueden verse juntos y cruzarse.
Suena simple. Es estructuralmente significativo.
Cuando la acumulación de GDD se sigue junto al programa de nutrición, puedes ver si la aplicación de fertilizante coincidió con la ventana de crecimiento o la perdió. Cuando los modelos de riesgo de enfermedad se alimentan de datos meteorológicos reales del sitio en vez de un pronóstico regional, la evaluación del riesgo refleja tu microclima, no un promedio de 30 km. Cuando los registros de pulverización llevan marca de tiempo frente a las condiciones meteorológicas, puedes auditar si las aplicaciones se hicieron en la ventana correcta — y si funcionaron.
Cómo se ve esto a las 6 de la mañana: abres un solo sistema. Ves que las temperaturas nocturnas bajaron a 3 °C, que la humedad del suelo en los greenes está al 28 %, que la acumulación de GDD ha cruzado el umbral que fijaste para tu próxima aplicación de fertilizante, y que el modelo de riesgo de enfermedad a 10 días muestra presión elevada de fusarium a partir del jueves. El registro de pulverización indica que tu última aplicación preventiva fue hace 12 días.
Estás tomando las mismas decisiones. Pero la preparación que antes llevaba 20 minutos de cruzar datos entre cinco sistemas ahora lleva 90 segundos de lectura. Y lo más importante: los cruces que podrías haber pasado por alto — porque estabas ocupado, porque olvidaste comprobar la sonda de suelo, porque la hoja de cálculo estaba en el ordenador de la oficina — ahora son visibles por defecto.
El paso de la Etapa 1 a la Etapa 2 no va sobre mejores datos. Va sobre liberar al operador del trabajo manual de integración para que pueda centrarse en aquello en lo que realmente es bueno.
Etapa 3: Inteligente
La Etapa 3 es cuando el sistema deja de ser un archivador — incluso uno bien organizado — y empieza a razonar.
En la Etapa 2, el sistema te muestra que el GDD ha cruzado tu umbral de nutrición. En la Etapa 3, te dice: "El GDD ha cruzado el umbral esta mañana, pero la humedad del suelo es baja y no hay lluvia prevista durante cinco días. Aplicar fertilizante granular ahora conlleva riesgo de quemado. Considera retrasar 48 horas o cambiar a una aplicación foliar."
En la Etapa 2, ves que la presión de enfermedades está subiendo. En la Etapa 3, el sistema ya ha revisado tu registro de pulverización, ha comparado las condiciones con patrones históricos de tu sitio, y te ha dicho: "Las condiciones evolucionan de manera similar a la tercera semana de octubre de 2025, cuando apareció fusarium en los greenes 6, 11 y 14. Tu última aplicación fue hace 12 días. Te acercas al final de la ventana de protección."
Esto no es automatización. El operador sigue decidiendo. Pero el sistema ha hecho el trabajo de preparación que antes dependía por completo de la memoria y la experiencia — a través de cada dato, cada registro histórico, cada modelo meteorológico, simultáneamente.
Cómo se ve esto a las 6 de la mañana: llegas y el sistema ya ha preparado un briefing basado en los umbrales que fijaste, las prioridades que definiste y el plan de gestión que construiste para la temporada. Esto es lo que ha cambiado durante la noche. Esto es lo que significa respecto a tu plan. Estas son las tres cosas que requieren tu atención según tus propios criterios. El resto va según lo previsto.
El greenkeeper experimentado sigue sabiendo más que el sistema sobre las sutilezas de su sitio — el green que siempre drena despacio, el microclima detrás de la casa club. Pero ya no está gastando esa experiencia en el trabajo manual de integración de datos. Su conocimiento va donde es realmente insustituible: el juicio, las prioridades y las mil pequeñas decisiones que hacen a un gran campo.
La cabina, no el piloto
La Fórmula 1 pasó exactamente por esta transición. En los años 80, un estratega de carrera tomaba las decisiones de parada en boxes con un cronómetro, un tablero de boxes y la voz del piloto por la radio. Los datos existían en fragmentos — el piloto sentía los neumáticos, el mecánico oía el motor, el estratega miraba la diferencia de tiempo. Nadie tenía una visión conectada.

Hoy, 300 sensores por coche generan más de un millón de puntos de datos por segundo. Los equipos ejecutan más de mil simulaciones de carrera por fin de semana. La diferencia no es que hayan añadido sensores. Es que han rediseñado la arquitectura de decisión en torno a datos integrados y en tiempo real.
Pero el piloto sigue pilotando. El coche sigue teniendo que sentirse. El instinto que separa una buena vuelta de una gran vuelta no ha sido reemplazado — ha sido amplificado. El piloto no compite contra la telemetría. La telemetría le da al piloto más parte del cuadro, más rápido, para que las decisiones que solo un humano puede tomar ocurran con mejor contexto.
Ese es el cambio. No reemplazar la experiencia. Amplificarla eliminando el trabajo de datos que se interpone entre lo que sabes y lo que haces.
Hacia dónde va esto
El destino no es un sistema que reemplace al operador. Es un sistema que le acompaña — un copiloto que está presente durante toda la temporada, que construye contexto con el tiempo, que entiende la diferencia entre marzo en tu sitio y marzo en un sitio a 200 kilómetros de distancia.
Cuando las decisiones se toman dentro de un sistema conectado, dejan rastro. La aplicación de fertilizante que se retrasó porque la humedad del suelo era baja — esa decisión queda registrada, junto con las condiciones que la motivaron y el resultado que siguió. Con el tiempo, el sistema aprende. No desde un libro de texto — desde tu césped, tu clima, tus decisiones de gestión. Cada temporada hace más afilada la siguiente.
Las fábricas que acabaron prosperando no fueron las que compraron los mejores motores. Fueron las que replantearon cómo se organizaba el trabajo. La tecnología importaba — pero la arquitectura importaba más.
Para la gestión del césped, la pregunta equivalente no es "¿qué sensor debería comprar después?". Es: "cuando la información llega a mi sitio — desde una estación meteorológica, una sonda de suelo, un registro de pulverización, una medición de crecimiento — ¿adónde va y qué pasa con ella?".
La tecnología para responder bien a esa pregunta existe hoy. La cuestión, como ocurrió con el motor eléctrico, es si estamos dispuestos a replantear la arquitectura en torno a ella.