Het probleem van het sentinel-netwerk
Geschreven door
Valentine Godin

Oorspronkelijk gepubliceerd in het Engels.
Wat zestig jaar van hetzelfde formulier mogelijk maakt
In de winter van 2008 deden ongeveer honderd huisartsenpraktijken in Engeland wat ze elke week doen: een korte gestandaardiseerde rapportage indienen bij Public Health England. Het rapport vraagt één ding: hoeveel patiënten meldden zich deze week met een nieuwe episode van acute ziekte, een temperatuur boven 38 graden en ten minste één luchtwegklacht? Niet «hoeveel mensen leken ziek». Een gedefinieerd geval. Een vaste drempel. Hetzelfde formulier, in elke praktijk, elke week, sinds 1967.
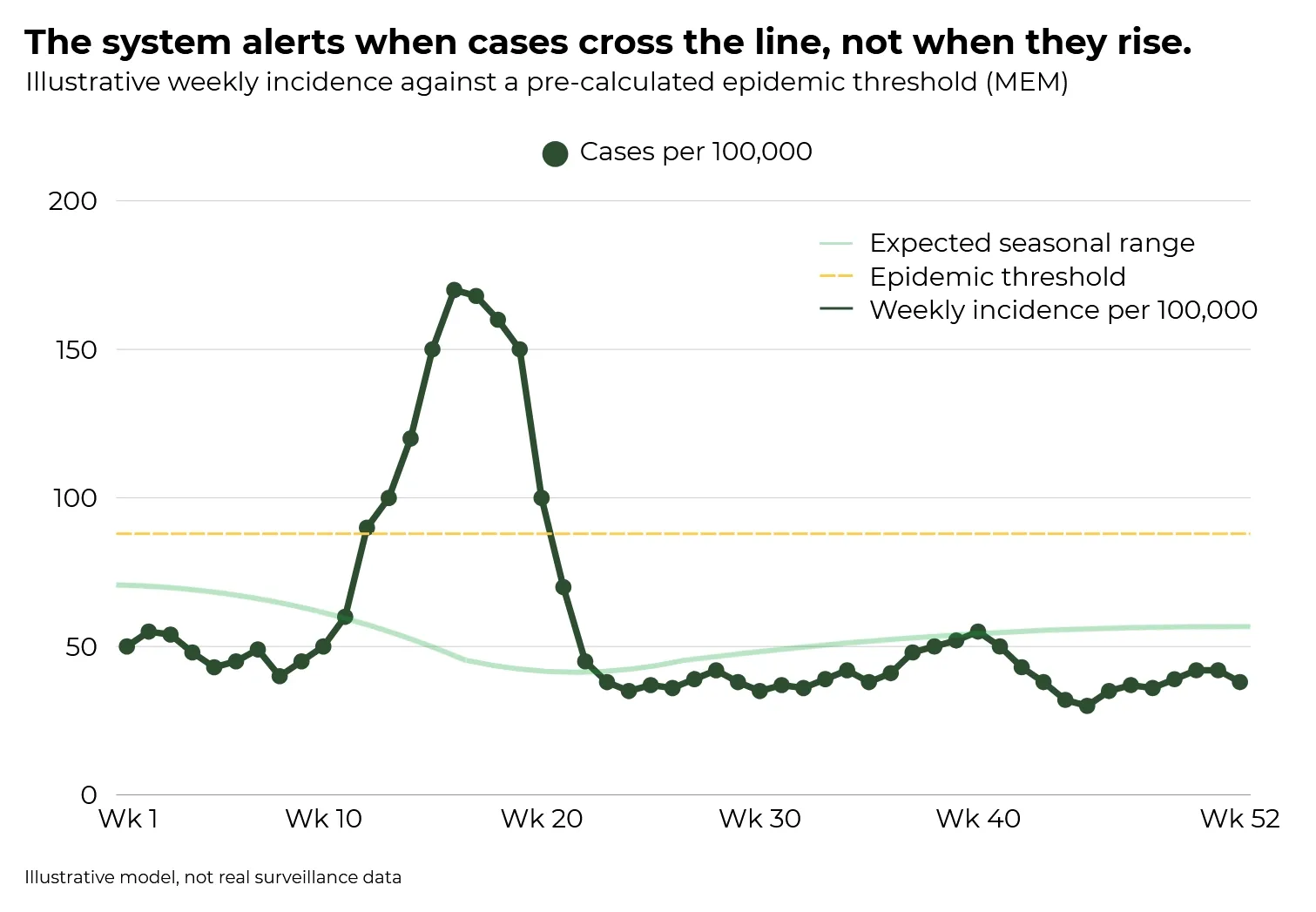
In april 2009 overschreden de wekelijkse meldingen uit die praktijken een drempel. De incidentie was uitgekomen boven de vooraf berekende epidemische basislijn in een ongebruikelijke demografische groep, in een patroon dat niet paste bij de seizoensnorm. Laboratoriumbevestiging was nog niet binnen. Er was geen klinische aankondiging gedaan. Het systeem had al geregistreerd dat er iets was veranderd.
Vroege detectie was een functie van continuïteit, niet van capaciteit: hetzelfde formulier, elke week ingediend, tweeënveertig jaar lang.
Wat een sentinel-netwerk laat werken
Het RCGP/UKHSA-griepsentinelsysteem is geen technologieverhaal. De praktijken gebruiken gewone klinische dossiersystemen. Het wekelijkse rapport is een spreadsheet. Het signaal komt niet voort uit geavanceerde infrastructuur maar uit twee principes die samen werken.
Ten eerste: elke waarnemer gebruikt dezelfde casusdefinitie. «Influenza-achtig ziektebeeld bevestigd» betekent in Exeter hetzelfde als in Newcastle. Ten tweede: de gegevens worden uitgedrukt als incidentie per 100 000 inwoners in plaats van als ruwe aantallen, waardoor regio's van verschillende omvang direct vergelijkbaar zijn. Een plattelandspraktijk en een stadspraktijk leveren gelijkwaardige waarnemingen.
Op basis van die vergelijkbare dataset berekent het systeem een statistische basislijn met de Moving Epidemic Method (MEM), ontwikkeld door Tomás Vega en collega's en nu in gebruik in het surveillancenetwerk van het ECDC dat dertig landen omvat. De MEM definieert niet alleen een gemiddelde maar een drempel: het punt waarop de wekelijkse incidentie van normale seizoensvariatie is overgegaan in epidemische activiteit. Het systeem alarmeert niet wanneer het aantal gevallen stijgt. Het alarmeert wanneer de gevallen de vooraf berekende lijn passeren.
Dit is het cruciale onderscheid. Het sentinel-netwerk standaardiseert de behandeling niet. Hoe elke huisarts een individuele patiënt behandelt, verschilt enorm. Wat wel wordt gestandaardiseerd is de waarneming: wat geldt als een geval, wat de drempel is, welke condities erbij horen. Vervolgens past het een statistisch kader toe dat definieert wat als signaal geldt tegenover de verwachte achtergrondruis.
Het ECDC bracht hetzelfde principe naar continentale schaal. TESSY, het Europese Surveillance Systeem, verzamelt sinds 2008 gestandaardiseerde surveillancegegevens over 52 overdraagbare ziekten in 30 landen. Wat het laat werken is niet de technologie; het is dat elk land dezelfde waarneming in hetzelfde formaat indient, en de inzichten die daaruit ontstaan zijn eenvoudigweg op geen enkele andere manier beschikbaar.
De kloof in de turfsector
Elke greenkeeper houdt een spuitdagboek bij. Veel ervan zijn inmiddels digitaal. Tussen verschillende terreinen zijn die registraties zelden zo gestructureerd dat ze vergelijkbaar zijn met die van een ander.
«Dollar spot aanwezig» in de registratie van het ene terrein betekent dat de superintendent om 6 uur 's ochtends het eerste wattige mycelium op het blad heeft vastgesteld, voordat de dauw was opgedroogd, voordat zich enige vlek had gevormd. Op een ander terrein beschrijven dezelfde woorden reeds gevestigde strogele vlekken over meerdere greens, zichtbaar en meetbaar in oppervlakte. De eerste registratie is een vroege waarschuwing. De tweede is een voortgangsrapport. Beide beschrijven dezelfde ziekteverwekker die actief aanwezig is op het terrein. De waarnemingen kunnen drie tot vijf dagen uit elkaar liggen in de ontwikkeling van de ziekte, en er is geen gedeelde ernstschaal die ze met elkaar verbindt.

Dit is geen dataprobleem in de gangbare zin. De data bestaan. De waarnemingen gebeuren. De beheersbeslissingen worden genomen en vastgelegd. Het is een structureel probleem: van de registraties van die waarnemingen is nooit geëist dat ze op elkaar aansluiten, niet tussen terreinen en, belangrijker nog, niet binnen één terrein over de seizoenen heen.
Het onderzoek naar plantenpathologie beschikt al decennia over gestandaardiseerde protocollen voor ziektebeoordeling: de Horsfall-Barratt-schaal, percentage aangetast oppervlak per gedefinieerde beoordelingseenheid, gestructureerde ernstbeoordelingen. Ze worden gebruikt in proefwerk. De disconnectie is dat ze niet vanuit onderzoekscondities zijn doorgedrongen tot de dagelijkse praktijk, consistent en op schaal.
Het gevolg is een zeer specifieke informatiekloof. Een superintendent die dollar spot bestrijdt op een agrostisbaan in Surrey gedurende drie opeenvolgende junimaanden beschikt over gegevens die mogelijk waardevoller zijn dan welk generiek risicomodel ook. Maar tenzij die toepassingsregistraties zijn gekoppeld aan de omstandigheden die aan de behandeling voorafgingen (de op dat moment opgebouwde risicowaarde, de uren bladvochtigheid, de nachttemperaturen, het stikstofprogramma van de voorgaande weken), kan het patroon niet worden ontleed. De data bestaan. De structuur die ze bruikbaar zou maken, niet.
De individuele datalaag is al een voorspellend systeem
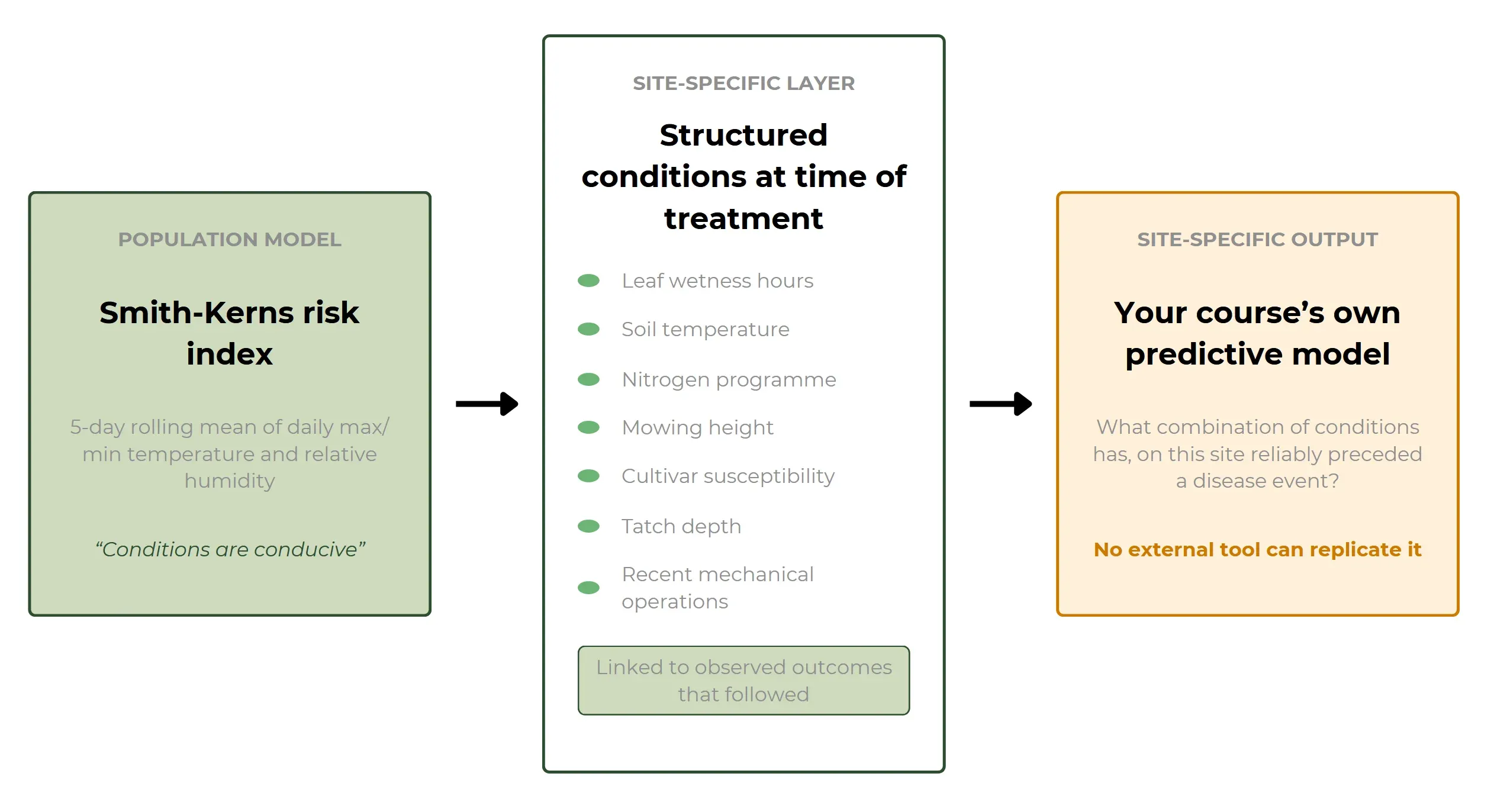
Het Smith-Kerns Dollar Spot Prediction Model, ontwikkeld aan de North Carolina State University en gepubliceerd in Plant Disease in 2018, genereert een risicowaarde op basis van een voortschrijdend gemiddelde over vijf dagen van de dagelijkse maximumtemperatuur, minimumtemperatuur en relatieve luchtvochtigheid. Het is het meest rigoureus gevalideerde voorspellende model voor deze ziekteverwekker en het werkt, maar het werkt als een instrument op populatieniveau. Het voorspelt gunstige omstandigheden, geen infectiegebeurtenissen. Het kent niet de gevoeligheid van jouw cultivar, de stikstofdynamiek van jouw bodem, de dikte van jouw viltlaag of de beheergeschiedenis die de specifieke respons van jouw locatie op die omstandigheden heeft gevormd.
De kloof tussen «de omstandigheden zijn gunstig» en «de ziekte zal op jouw greens verschijnen» is precies de kloof die locatie-specifieke gestructureerde data dichten.
Wanneer spuittoepassingen in een gestructureerd systeem worden gekoppeld aan de omstandigheden op het moment van behandeling (de risicowaarde, de uren bladvochtigheid, de bodemtemperatuur, de stikstoftoedieningen, de maaihoogte en eventuele recente mechanische ingrepen die de zode kunnen hebben gestrest) en aan de waargenomen resultaten daarna, kun je een vraag stellen die geen enkel generiek model kan beantwoorden: welke combinatie van omstandigheden ging op deze specifieke locatie in de afgelopen drie seizoenen betrouwbaar vooraf aan een ziekte-episode?
Het antwoord op die vraag, ontleend aan de eigen gestructureerde registraties van een terrein, is al een locatie-specifiek voorspellend model dat geen extern hulpmiddel kan repliceren, omdat het is opgebouwd vanuit precies de grond waarover wordt gevraagd.
En het reikt verder. Wanneer dezelfde gestructureerde data voedingsinput koppelen aan groeirespons, bodemtoestand aan infiltratiesnelheid, beheerbeslissing aan meetbaar resultaat over een volledig seizoen, heeft het terrein iets nuttiger opgebouwd dan welk extern model dat is gekalibreerd op een verre populatie banen ook: een steeds preciezere registratie van oorzaak en gevolg op de eigen grond.
Dit is de individuele datalaag die ertoe doet. Ze vereist geen nieuw rapportage-initiatief. Ze vereist dat de gegevens die in het normale beheer al worden verzameld, worden gestructureerd op een manier die ze koppelbaar, doorzoekbaar en vergelijkbaar maakt in de tijd.
Wat er in 1967 werkelijk werd uitgevonden
Beoefenaars van de infectieziekten observeerden al eeuwen patronen voordat het sentinelnetwerk van huisartsen bestond. John Snow bracht in 1854 de cholera-uitbraak in Broad Street in Londen in kaart. William Farr publiceerde vanaf 1839 statistische analyses van sterfte per oorzaak bij het General Register Office. De waarneming was niet nieuw.
Wat in 1967 veranderde, was niet de waarneming. Het was de standaardisering van wat als waarneming gold, en de architectuur die individuele waarnemingen op regionale schaal vergelijkbaar maakte.
Dat is een andere technologie dan de datatools die erop volgden. Het is ook, met grote afstand, de meer ingrijpende. Zonder de gedeelde definitie levert geen enkele hoeveelheid data-infrastructuur inzicht op. Met die definitie dragen individuele praktijken die hun gewone werk doen, zonder extra inspanning, bij aan een systeem dat kan detecteren wat geen enkele individuele beoefenaar alleen kan zien.
De turfsector verkeert in 2026 in de positie dat de beoefenaars er zijn, de data zijn er, en in toenemende mate ook de digitale infrastructuur. Het sentinelnetwerk hoeft niet apart te worden gebouwd. Het moet voortkomen uit de data-architectuur die goed beheer per locatie al rechtvaardigt, consistent toegepast, gekoppeld op schaal.
Bronnen: Smith-Kerns Dollar Spot Prediction Model, Smith et al., Plant Disease, 2018. Moving Epidemic Method, Vega et al., Influenza and Other Respiratory Viruses, 2013. Taxonomische herclassificatie van Clarireedia jacksonii, 2018. ECDC TESSY, ecdc.europa.eu/en/tessy. RCGP/UKHSA sentinelsurveillance, ukhsa.gov.uk. USGA Green Section onderzoek naar grasziekten, usga.org/course-care
Onderwerpen
Laatste artikelen
Terug naar alle berichten
Toen de machines dezelfde taal begonnen te spreken
Google bracht een protocol uit met de naam A2A (Agent-to-Agent), samen met een referentie-implementatie genaamd de Agent Gateway.

Wat "agentisch" betekent voor grasbaanmanagement
Uw weerdata praat niet met uw voedingsplan. Dit is wat dashboards scheidt van systemen die daadwerkelijk nadenken.